Messaging Brokers as a Single Point of Failure
As the software development community is getting more used to the idea that microservices are a valuable approach to solving business problems, we are getting more and more conversations about how these services should communicate.
I am a strong proponent of the benefits of Event Driven Microservices. While I don’t think there is a silver bullet that can solve all problems, I do think this approach is a valuable way of thinking about general business process modelling. It enables us to build reactive systems that can more easily evolve with the businesses they support.
Through my work in consulting I have a lot of conversations with people new to the idea of brokered messaging as a core platform for their systems, and one of the questions I get asked a lot is:
Does the message broker become a single point of failure for my system?
often combined with or followed by:
What benefit does it give us that justifies this ‘risk’?
Let’s take a look at what a message broker is and what it does for us. Then we can see if this question makes sense to ask, and what the answer is.
What is a Message Broker
A message broker is a piece of software (or sometimes an appliance) that sits between 2 or more of our services and passes messages (blobs of data) between them. They have a set of features which make them valuable for interprocess communication, namely:
- They can store messages reliable if the receiver is not able to process them when they’re sent. This is called Message Queueing
- They can receive a single message on a topic, and reliably distribute it to more than one recipient who have subscribed to that topic. This is called Publish/Subscribe
- They can deliver a message to a receiver and hold onto it till they confirm they have processed it. If they don’t it can re-deliver the message. This is At Least Once Delivery
Lots of message brokers have other features and message delivery patterns, but those the core ones that provide the most value to use.
What’s a Single Point of Failure?
When we are building software systems we want them to be reliable. Machines can fail and software can crash, so we have to build software that doen’t lose data or cause outages when they do.
One of the best ways to ensure that things can continue to work when one thing fails, is redundency, meaning to have more that one them. If we dont have more than one, we have a single place in our system that can fail, and when it does, it all stops working. That is our single point of failure.
What are systems like without message brokers?
Without a message broker we normally build software components that talk directly to each other. Service A needs Service B to do something, so it calls Service B across the network and tells it what it needs.
This is fairly simple. However, we said we want to make thing reliable, so we need to have more than one of these services to give us some redundancy.
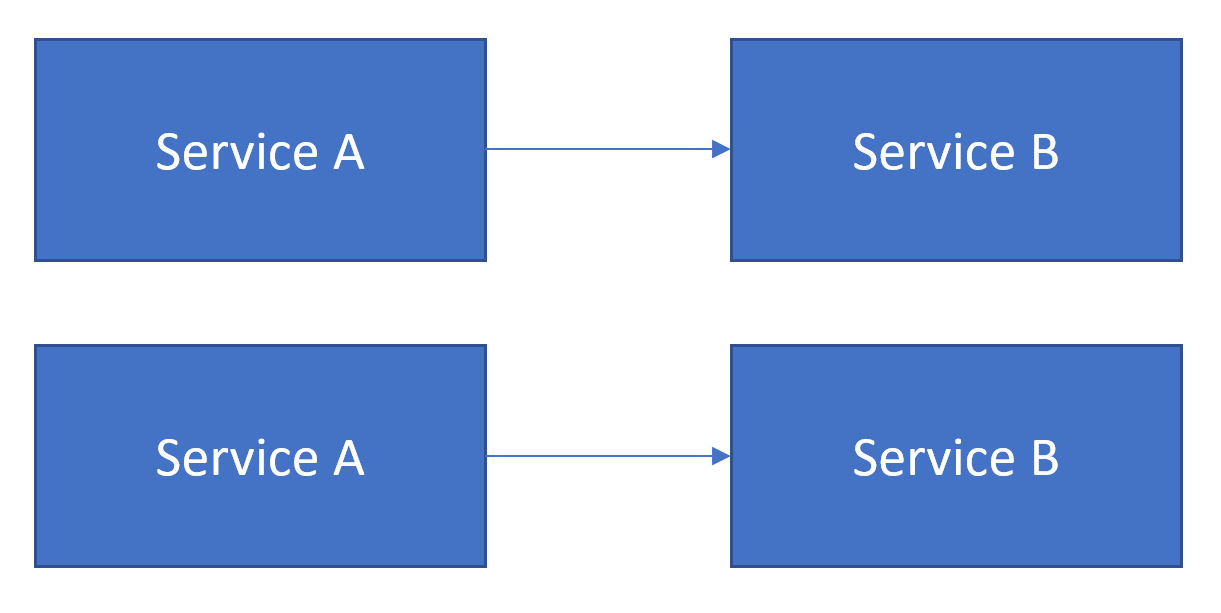
This is better, we now can tolerate the failure of a Single Service A and potentially the other Service B. But we could do better. If we make each Service A talk to both Service B instances, then we could tolerate 1 Service A and one Service B failing. We still have some problems though, plus some new ones:
- Clients of Service A need to know the address of each instance of Service A.
- We need to make sure that Service A knows how to find all the Service B instances.
- Our Service Clients need to be able to retry their request if it fails. This can lead to SLA challenges if you call multiple Service A, which calls on to Service B, then that fails, so it calls another, and so on.
- The requests that are being processed during Service A’s failure will still fail.
We can solve some of these problems though with other means:
- We could use a Domain name for Service A and Network Load Balancing.
- We could use a service registry to allow Service A to find instances of Service B.
- We could wrap the whole thing with a reverse proxy that would handle the client rety logic etc.

This is now a more resilient architecture, however, we now have some infrastructure components that are key. DNS, Reverse Proxy and Service Registry. We will need to make sure these things are reliable. We can configure them easily enough and then use NLB and similary techniques to make them reliable too.
However, we still have some challenges with reliability that we will need to solve ourselves:
- In process requests to a service that fails need to be manually detected and retried by the requestor.
- What if Service A needs to tell Service B and Service C to do something, how do we make sure both those requests get through?
Fixing these problems will require us to write a lot of code to get a half good solution.
So are we concerned with SPOF?
Any reasonably complex system (more than 3 parts) will need to solve ‘single point of failure’ problems. The more complex the system, the harder that challenge is, as everything needs to be made reliable.
As we see above, whether you have a message broker or not, you will need to make sure your critical pieces are reliable.
So the big fear over Message Brokers being a single point of failure doesnt make sense, its a Red Herring argument which people bring up because they haven’t properly reasoned about their options.
So if we can now agree that complex systems need solutions for inevitable SPOF situations, lets look at the second part of the question. Do messages brokers provide us with value?
Are messages brokers good for us?
Remember that list of features of a message broker? Let’s revisit that and look at how we can use a message broker to solve a lot of the problems we have with complex systems:
- Service Discovery: We can use the Pub/Sub model with Topics and Subscriptions to prevent the need to know where are services are. They are just on the end of a topic.
- Detecting Failures: We can use the At Least Once Delivery Mechanism to enable a ‘Competing Consumer’ pattern for our Services. This means that if a service dies while procesing a request, another will get that message from the queue and process it. This happens without you having to write any code.
- More than one Service?: Again we can use Pub/Sub to provide to let Service A get a message/request to both Service B and Service C with just one operation. The message broker handles reliably distributing to many consumers. In fact, new cosumers can be added without Service A having to know about it.
- One of the challenges, or reasons for failure, with services can be handling load. The Queueing feature of the message broker makes that simpler too. We can just consume messages as fast as we can and the broker will spool them for us. If we need more processing power we can increase the number of consumers processing them.
So we can see that message brokers do provide us with a lot of value. They can be used to solve a lot of hard problems that we have when writing distributed systems.
My caveat that I always like to include in message broker recommendations. Try to avoid using the vendor specific bells and whistles that might be in a particular message broker which sound great in the sales pitch. While they may do some impressive feats, they come at the expense of portability, and sometimes testability/DevOps. I’ll post more on this in the future, but remember one of the core tenants of microservices thinking is ‘smart endpoints and dumb pipes’, so try not to make the platform too intelligent.
Making Message Brokers reliable
Each message broker has a different method for becoming reliable. These are normally some form of clustering that makes multiple machines run as a single broker cluster so failure of one doesnt mean total failure.
However, cloud providers like Azure have Azure Service Bus that takes a huge amount of this burden off you. There is still some work to do when you want to be tolerant of an entire region failing, but for the most part they offer a reliable scalable broker as a service.
Summary
To summarize, while a lot of people fear message brokers being a single point of failure, the truth is that all complicated systems end up with critical components. You always need to make these reliable.
So rather than avoid Message Brokers, use them for all their benefits, and take a little time to make yours reliable. Or perhaps better yet - get one as a service.
Comments