Business Messaging on Azure
One of the current trends that we are seeing in Business system engineering is a move to Event Driven architectures. This architectural style eschews the normal service to sevice relationships of direct synchronous RPC style API calls in favor of pushing out ‘Events’ through a Pub/Sub middleware.
This change in the relationship is often described as ‘Choreography’ over ‘Orchestration’.
Working at Avanade, most (not quite all) of our Clients are looking to build these systems on Azure using a native service. One of the more challenging questions that I’m starting to see is:
Should I use Service Bus or Event Hubs?
This is a tough question to answer, and it depends a lot on the requirements of the business problem you’re trying to solve.
How do we solve it?
I think the most important way to understand this problem, is to get to know a little about the candidate technologies. They have each been created with a specific problem to solve. Therefore they will naturally make a good fit if your problem is like that original problem. They might also be able to help with other problems though as they are quite flexible tools.
Type of Broker
I think its good to understand that there are different types of message broker. Fundamentally I think there are really two types, or at least there are in this short list.
I refer to them as an AMQP Broker and a Distributed Log
AMQP Broker
An AMQP broker is the more traditional style message broker, sometimes (formerly?) called Message Oriented Middleware. Like: ActiveMQ, Solace, RabbitMQ, IBM MQ, Tibco, Azure Service Bus, Event Grid, and many, many others.
The below is an image I made for internal training (it was a powerpoint animation) that showed
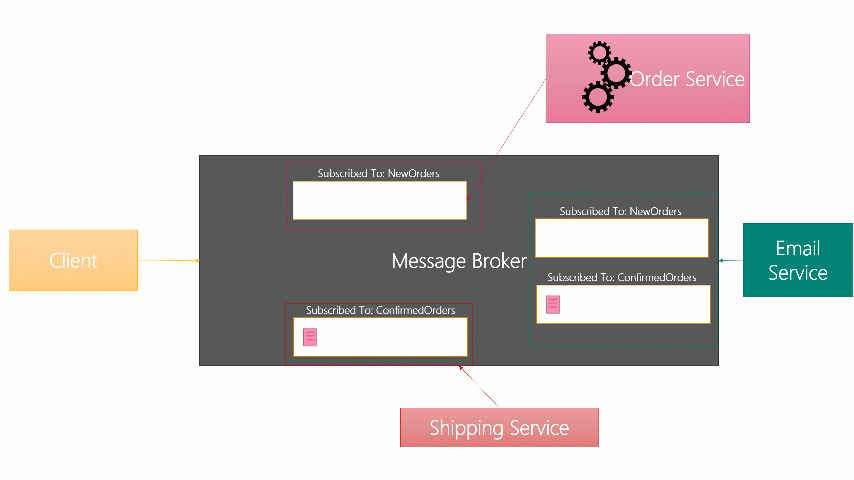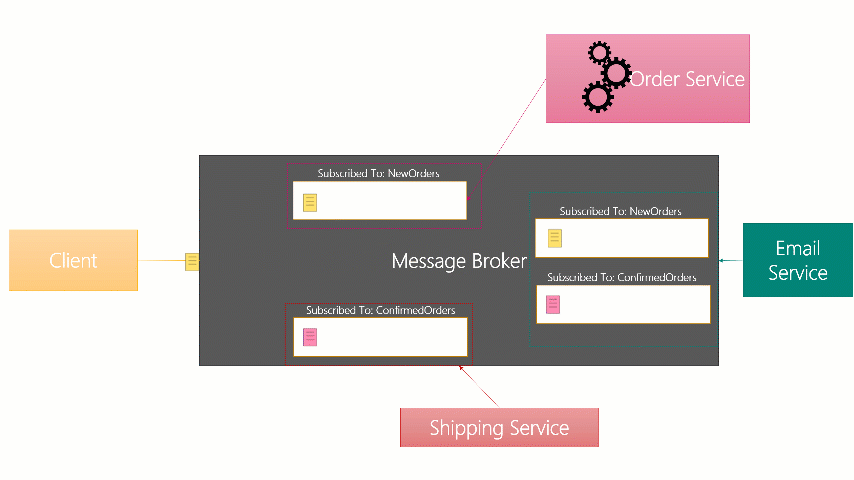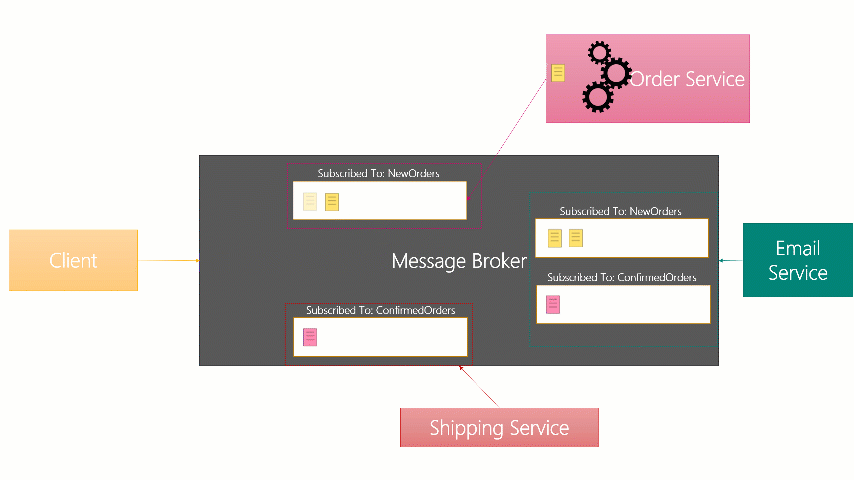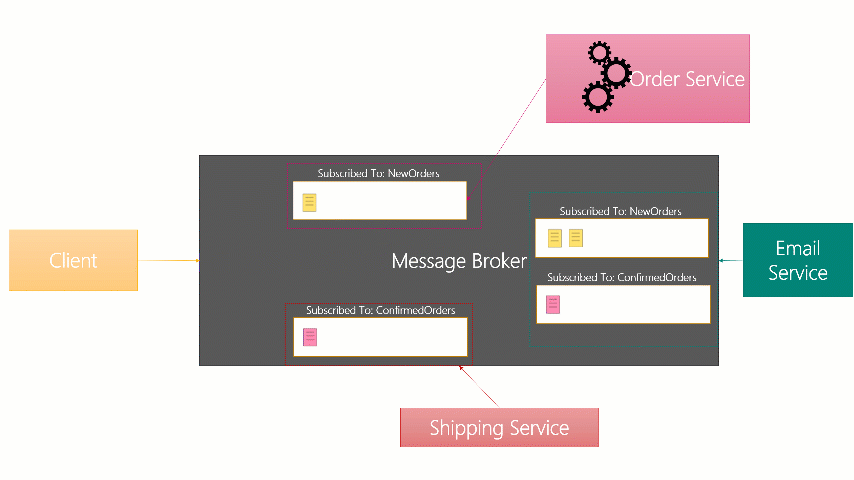
Although the internal implementations vary, the basic idea is still the same across these brokers.
- Different Receivers that want to receive messages create a subscription to them with the broker
- The broker creates a Queue structure to hold messages to send to the subscribed parties
- A message sender sends messages to the broker with a Topic (or Subject) for the message.
- The message is placed into each of the Subscription Queues for the Subscribed receivers
- When a receiver is connected and ready to receive a message, a copy of it is forwarded to them.
- It remains on the queue, but locked, while they process it.
- Once they have processed it, they send an acknowledgement to the broker and it’s removed from their Subscription (forever!)
- If they dont Acknowledge it, because of disconnect or error, the message will be redelivered to them next time.
A number of these types of brokers speak different protocols. AMQP is a standard protocal, but there is also STOMP, MQTT, HTTP, XMPP, and others.
These brokers allow you to implement the Publish/Subscribe pattern through Topics and Subscriptions. They also often allow direct 1-to-1 communication with Queues but I won’t cover that much as its not a good pattern for business system messaging.
Distributed Logs
Kafka is probably the most well known Distributed Log type of message broker, invented by employees at LinkedIn. There are lots of good write ups about Kafka and how LinkedIn made it to help them scale. Azure Event Hubs is also a Distributed Log type of broker.
The underlying basic idea of all these types of brokers is the Commit Log. This basically is like a big long file that new thinks keep getting written to the end of. The Log is like a Topic in the other kind of broker. You put lots of events that are the same type of thing in a single topic.
In order to help it scale, all of these brokers actually break the file up into partitions. This lets you group similar events together by source or relevant key, so you can scale the writing and reading, but also maintain some ordering where important.
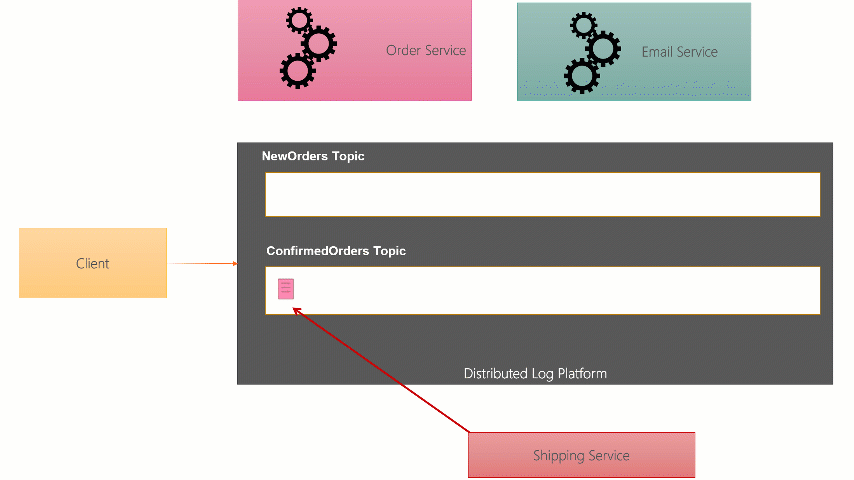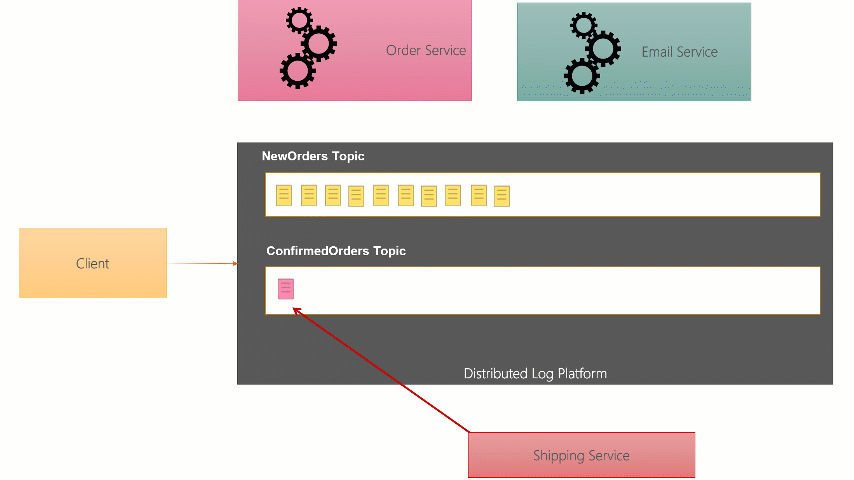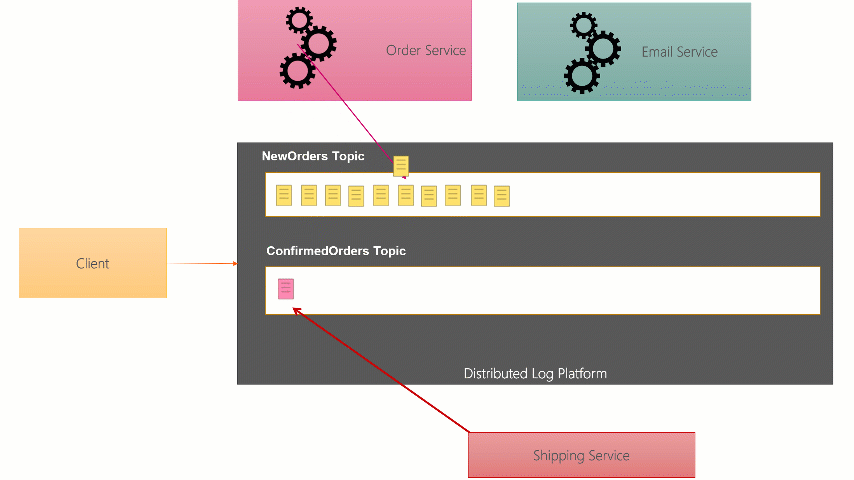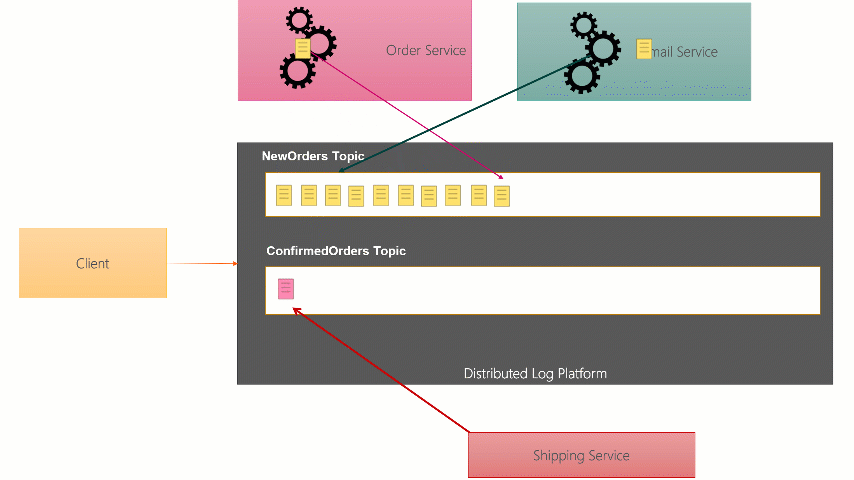
With this type of broker, as the message Producer sends the message to the broker, it writes it to the end of the Topic Partition file on disk. It also probably gives a copy to two back broker instances who write a copy too. When they Consumer of the message wants to receive it, it can ask for the next message on the Topic but passing the ‘offset’ (like a message number) that it’s read before. If it hasn’t read before it can start at the beginning.
Because of this difference, anyone at any point can chose to read from any point in the Topic. Messages arent deleted when they are read, they are left there for a certain amount of time (up to a week on Event Hubs, indefinitely on Kafka).
So What do we use?
Service Bus
Azure Service Bus is the primary mechanism for “Business Eventing”. When every event is important, and makes a different to a business state machine. When you are building a microservices, and they need to communicate with each other through messages.
In lots of microservice implementations I have seen and worked on, we have used Event messages to propagate state change. One of the ways of keeping each microservice database in sync in through these events. We can replicate data changes from on service into ‘cache’ records in other microservices databases in order for each service to own its own up time.
I have also built systems that use the Saga pattern for distributed transaction management. There are command, or request, type messages that trigger actions. There are response, or event, type messages that say that things were successful or failed. These are all important messages that need to be processed. They need to be distributed to and received by our services that need them in a reliable way.
These are very traditional use cases for Event Brokers. They are the sort of things that you might be doing with your on premise brokers right now, like RabbitMQ or ActiveMQ. These use-cases continue to be the target for Azure Service Bus.
But what about message retention?
I have had this question come up a few times about message retention on Azure Service Bus. It’s a Distributed Log feature that people seme to really like the idea of. You can tell your message receiver to rewind in the Log and start reading events again, from the beginning, or from whereever you like.
This is a cool feature, and I can think of lots of ways to get benefit from it:
- The ability to test & debug services with a set of production messages. Thats pretty cool
- The ability to copy the entire log to another environment and rebuild the state in that environment
- The ability to add services to an ecosystem and use the log as a way for them to ‘catch up’ with what they missed.
These are all cool sounding features of the Distributed Log. However, they aren’t all as clear cut easy as you think. Here is a counter to each:
- You normally can’t do this because of PII, HIPAA, PCI, GDPR, or other regulatory requirement to scrub data
- The Distributed Log is not normally retained forever, that could be a LOT of disk space. Plus see #1
- See #2 - the log normally isn’t long enough to do full and complete event sourcing. It’s often easier to purposely do event sourcing and then abstract the message source away to enable it to be a database priming tool.
Another side note for #1 and #2 - Distributed Log is generally considered ‘Data at Rest’ (because its stored in a file in a persistant disk) and therefore needs to be able to be encrypted, secured, backed up, and purposely forgotten in line with regulations.
Event Hubs
Event Hubs is effectively Kafka on Azure. That is to say whatever you do with Kafka, Event Hub should be there for you. That also means that Event Hub is good for the same things. So what is Kafka and Event Hub good for?
BIG DATA
Well that’s a bit cliche! It’s good for getting LOTS of similar of data pumped through a system. Remember Kafka was created in order to get Log information from lots of machines to come together in a single place. Event Hub is good for that same thing. The log doesnt have to be weblogs, or service process logs (but it can). It can be IoT data, weather data samples, database change data, website orders, anything.
The difference between ASB and Event Hubs is that Event Hub is really designed for a one way type of thing. Getting lots of data from A to B. Not so much from B back to A, sometimes to C, with a little from D, E, F, G, all in an ellaborate choreography. It’s like a huge funnel to take lots of stuff from lots of places and make it available to relatively few.
A good example is using it to ingest all the searches that happen across a large ecommerce website and what gets clicked on. This data can all get pumped into a data lake for storage, plus it can simultaneously be pumped into a stream analytics job to try and do some live calculations on demand.
This is where the storage comes in useful. They models can be AI driven, they can be adapted and re-run, across all the data if need be. I could write new ones from scratch and run them across the data too. It wont matter that I only have 7 days of history, I am more about trends than specific records. In fact, thats a key point: Event Hub will delete data that is too old, even if nobody read it. That might be a problem for business messaging. It can hold up to 7 days of data though, you should spot can outage before that :)
But people use Kafka for business messaging all the time
Yes. Yes they do. And that’s ok. Event Hubs can do that too. In fact, you can point the Kafka client in your system at an Event Hubs Namespace and it will work like a Kafka broker. Creating topics people publish too as needed, storaging messages the same way, and scaling out pretty well. If you are going to use Event Hubs this way, you should be thinking of the Dedicated plan. In the same way you would have a dedicated Kafka cluster.
So Event Hubs can do this, natively and through the Kafka API, but it isn’t really what Kafka or Event Hubs was intended for. Infact, it reminds me a lot of the early MongoDB sales talk: “use Mongo because joins are slow, Mongo doesn’t join so it’s fast”. Joins weren’t actually that slow. Mongo was talking about early MySQL that only had nested loop joins. SQL Server had other join types like hashmap joins which were much faster. I feel like a lot of people use Kafka because their single machine, default configuration ActiveMQ machine didn’t scale how they wanted, so they pick up a 6 machine Kafka & ZooKeeper cluster and it runs faster. I’m not saying Mongo isnt useful and Kafka/Distributed Logs aren’t very fast, but they aren’t the solution to every problem.
Summary
When you have business processes, state machines, Sagas, Request Response, or anything other complex messaging patterns default to Azure Service Bus
When you have data ingestion, large scale event streams, change data capture, IoT, event stream replay use cases, or other bigger data requirements - use Event Hubs.
If you have Kafka and want to point to a PaaS service - use Event Hubs
If you need Store & Forward type functionality from a local/on-prem messaging platform to a cloud one - You’ll need something like Solace or ActiveMQ rather than Service Bus, or Kafka combined with Event Hubs.
Comments