Occasionally Connected Servers - A Whitepaper
The Occasionally Connected Servers pattern is a solution for a modern set of problems that arises from the increasing desire of business to provide high quality, data and content rich, connected experiences for their customers and employees across a distributed set of locations.
This whitepaper describes a set of technology patterns that collectively solve this problem through the creation of server applications that are designed for the intermittent and high latency connectivity experienced in geographic distribution scenarios.
What’s the problem we have?
There are quite a few different industries that have a similar class of problem, requiring a similar class of solution. A high-level summary is that there are different locations where the business meets its customers and it wants to create richer, more data driven experiences while catering to the high latency and lower reliability of its connections to its central infrastructure.
Some examples:
Retail
Lots of retail companies are creating their own applications for both staff and customer use. Staff are increasingly using phone and tablet based POS systems for checkout and inventory searches.
Customer facing apps used to be a mobile app version of their website, but increasingly we are seeing demand for richer experiences:
Mobile apps are replacing the simple price checker machines that used to be screwed to various columns in a larger store. Kohls in the United States does this.
Target lets you scan items as you put them in your cart and tells you if there are coupons for them. Then when you check out you scan the app to apply all the coupons.
Some retailers (e.g. Sam’s Club) mobile apps let you scan things as you put them in your cart to checkout without lining up.
The regular mobile apps have loyalty programs, discounts and rewards redemptions, and search features that give instore routing to the correct shelf when looking for a product.
There are many ‘art of the possible’ visions for retail that show digital signage personalizing to customers, digital changing rooms, drop boxes for online orders, even A.I. and computer vision based intelligent stores that automatically track shoppers, shelf inventory, and providing real time incentives and pricing.
Food Service
An increasing number of food service locations have some form of Kiosk in their restaurants. McDonalds and Burger King have these for ordering, while Chilli’s has them for tabletop drink ordering and payment.
Increasingly we’re seeing digital menu boards, kiosks, and mobile apps that can remove items from the menu automatically based on Out of Stock conditions. E.g. When a café runs out of bacon, it can remove it from the ingredients list on a salad, and entirely remove the Bacon Cheeseburger from the menu.
In some environments like airport restaurants there are increasingly tablet based ordering systems that allow you to order and pay without speaking to a person.
Paying the check through a mobile app is a great solution when a server is busy, and people hear their flight called.
Franchised Agency Industries
Employment agencies, Real Estate agencies, End of life services are examples of types of business where the work is typically done locally by an office of a larger corporation. The systems need to be able to run the business locally while reporting everything to the corporate main systems.
Common Architecture styles
Client Server Distributed
Commonly these experiences are being built using client/server patterns that have existed for decades. The experience is built as a thick client application that makes calls to server software across the network when it needs information. These are frequently HTTP based requests/responses with data transferred using JSON or XML.
For each of these types of business there is a local business process that happens at the location, and data that is managed centrally (e.g. Menu) and reported (e.g. Sales).
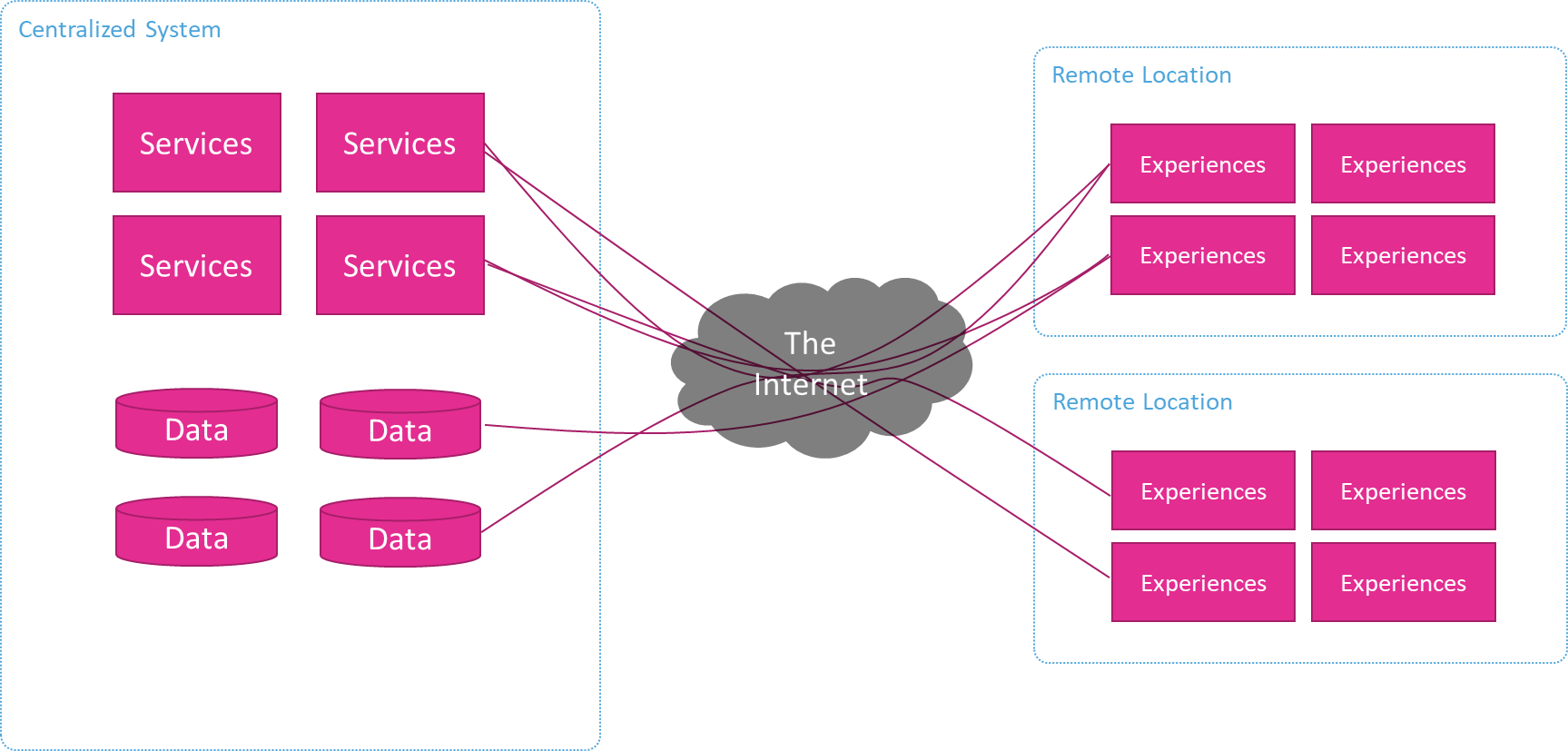
What’s wrong with this Distributed Client/Server pattern?
Bandwidth and latency
Most remote sites have connections with limited bandwidth and/or higher latencies. This means that requests between the clients and the servers can be slow and data exchanges can take a long time. Customers, however, are not patient and don’t normally want to wait or tolerate slow experiences.
This issue is compounded when the requests involve the transfer of large content like images or videos, such as when shopping and their results include product images.
Latency and reliability issues could also be a major obstacle to businesses effectively implementing IoT strategies or automated system integration
Connection reliability
As well as being low bandwidth and high latency these connections are often not reliable and can be lost entirely for periods of time. Many of the locations in retail, travel, and food service are in older or shared buildings (e.g. malls) and/or remote locations that were have been around much longer than high speed networking and they don’t have the quality of infrastructure you’d see in a corporate office or data center. This can be a major problem for customers who want to use experiences, redeem rewards, pay their check, etc. and can’t.
Oftentimes one of the benefits of these experiences to the business is that they enable them to reduce or reallocate staffing. When the connections, and therefore the experiences are down, they can’t do this. This unreliability prevents them from realizing their expected ROI.
Solving these problems
Lot’s of the existing systems in these industries have this capability. Leading Point of Sale systems are capable of operating for a couple of weeks without internet connection. They store the menu or product catalog locally, caching the orders they have taken and send them in when they get a connection again. Restaurant ones will also keep the kitchen displays and receipt printers working fine too.
However, there are limitations to what is accomplished this way. These COTS and POS systems typically can’t receive orders from kiosks or mobile apps while offline, their integration components don’t operate offline. They sometimes don’t even interoperate between the POS terminals, e.g. Orders entered on one might not be visible on others because they each keep their own local cache. This is commonly seen with marking items as Out of Stock or unavailable. It doesn’t synchronize this between registers when offline.
So, the geo-distributed client/server pattern is not suitable for these experiences. It can’t do the integrations that provide the differentiation.
Separate Local Systems
Another less common pattern people use to solve these problems is to have a separate installations of complete systems that live at the remote locations. These systems operate independently from each other, and then periodically synchronize their data back to a central database system through file transfers or long running ETL tasks.
This pattern often provides local employees and customers with low latency access to local data, however some of the use cases, like operating on non-local data, such as searching for inventory in other locations, aren’t possible.
It can also be challenging to manage the batch uploads and downloads, manage software versions, and check the health of the overall system.
What defines a good solution?
While the POS of sale screens may be able to keep running while the internet is offline, lots of other systems are beginning to have the same requirements.
Some of these experiences now potentially require a lot more information or intelligences to be able to work offline. In the Employment Agency - it might not be OK to only cache jobs from just that location, you might need them for the whole city, or the whole state, much more data than was synchronized before. These synchronizations are expected to be more frequent, not nightly like they typically have been in the past.
One other thing that’s different is that different systems in the same location are now expected to continue to integrate and interact while offline:
- Kiosks need to be able to put orders into the POS while offline.
- Digital signage needs to be able to remove out of stock items from the menu board.
- Customers still want to be able to scan offers from their mobile devices for rewards and discounts when the internet is out.
Requirements list:
We have a set of requirements that help us to define a good implementation of this kind of system:
- We want the system to be able to power experiences at the remote locations while disconnected from the central system.
- We want the local experiences to be responsive when online and offline
- We want the switch from Online to Offline to be invisible to the local experiences
- We want data to be replicated between central and remote stores, in both directions.
- This should happen in close to real time
- It should pause and automatically restart when the connection is lost/restored
- It should restart from where it left off, not the beginning of the batch/hour/day.
- We want local systems to be able to integrate with each other without going through a central location (so this works offline too)
- We want interactions to happen in real time, so new orders are printed immediately, and out of stocks update menu boards and kiosks in real time.
Do we need a new solution?
These distributed systems are not an entirely new, there are systems across the world that already achieve this functionality today and have done for years.
However, given the larger datasets, and the more integrations that need to happen locally, we need to look at modern ways to achieve this.
Occasionally Connected Servers
This is were we now see the Occasionally Connected Servers (OCS) pattern. This pattern is a combination of existing patterns and practices that have been developing in the last decade or two. Applying these together we can solve this specific category of problems and achieve these requirements. With these modern patterns and the software platforms that implement them it is now possible for any business to build systems that work this way.
The patterns that are used to build Occasionally Connected Servers are:
Event Driven Systems
Event driven systems typically control their processes through the publication of and reaction to events. Whenever big data has changed in these systems events are published so that all other microservices in the ecosystem can see those changes. This is become very useful for keeping our microservices database synchronized, but there is no reason this style of application cannot be applied to geographically distributed systems. Even keeping different copies of the same microservices In Sync with data updates being published by the cloud version and consumed by all the local deployed versions. Event driven systems allow us a great deal of flexibility if we keep the contracts for the events standardized and use send a message in technology to distribute the data events.
Message Brokers
These message brokers now come in several different flavors, from the more traditional message-oriented middleware, to the more recent development of ‘distributed log’ platforms. There are cloud Platform-as-a-Service offerings, container-based offerings, as well as software you can install bare-metal. They also range between free open source software and proprietary with the more common modern approach being free software and paid support.
It is likely the successful occasionally connected server implementation would require a central message broker hosted in the cloud as well as our locally installed message broker in each of their remote locations. Some message brokers (e.g. Solace PubSub+) will even perform storm forward operations between these different instances for you.
If that isn’t the case however you will need to implement synchronization logic between the brokers. You’ll need to receive messages from one broker and publish to the other while the Internet connection is available. When the Internet connection is unavailable, you’ll need to periodically retry that synchronization until the connection is restored.
Microservices
The microservices pattern that has been evolving over the last decade or so in the software industry has solved a lot of the patterns that are relevant to this problem.
Microservices are a pattern that drives us to create a set of independent, business focused, services/applications. They should be independent from each other, storing their own data, and managing their own lifecycle through automated testing and deployment, and they should be observable
Business Domain Oriented
A key principle of microservices, in fact the meaning behind ‘micro’ in the name, is that a microservice should be responsible for a single business domain, or bounded context. e.g. Customer or Product.
Monoliths of the past typically managed all these different areas of functionality inside the same code base, which mean interdependency between them was unavoidable. This increased the complexity of building, testing and deploying these systems.
These larger monolithic systems made it much harder to manage a distributed environment. While is the benefit that it’s just one application to manage, its a larger update to propagate, and its failure scenario is all or nothing.
Creating our domain oriented microservices in some ways makes is simpler to do the geographic distribution. While there is the obvious challenge of distributed systems, which are always hard, the hardest thing about it is making a single instance system become distributed. With microservices, distribution stops being an edge case that the teams solve for after the primary implementation and becomes the primary method for state change propagation.
For example, in a monolithic system you make the assumption that state changes happen in the processing, and the database your code has access to has the most up to date information in it, controlled in a regular database transaction. While implementing this logic it is unusual for developers to pause and think about the fact that this monolith might be one of many, and they will have competing updates, and need ways to propagate it. It’s not impossible to design monoliths like this, but it means having a duality of the local vs. remote models.
When building microservices, you do away with the local transaction model. You can’t commit a sale, with order, inventory, payment and loyalty updates in a single database transaction. You don’t have primary records of all those things in the same database and you don’t (shouldn’t) have access to the databases they are stored in. Therefore, the default mental model in this transaction implementation is distributed and collaborative. While a distributed transaction is harder to reason about than a local transaction, distributed is easier than distributed + local at the same time.
Storing their own data
As we just covered, Microservices store their own data for their own part of the business domain, their bounded context. However, they will almost always need data from other parts of the business domain and therefore will need to get it on demand or store a cache of it.
Getting data on demand means tying the reliability of the system together, like a distributed monolith, so it’s all up or all down. For this reason, it’s arguably better to have microservices cache the data they need from other bounded contexts. This gives us the problem that we need to keep that data in sync with the rest of the system. We have solved that problem well with Event Driven systems.
Event Driven systems use events to publish changes in state from each bounded context. These Events are typically messages distributed on an Event Broker e.g. Kafka, Solace PubSub+, Azure Service Bus, RabbitMQ, ActiveMQ etc. Now each service that needs information can cache its own copy, and keep it up to date by receiving these messages and committing the changes to their database/cache.
This works very well for reference data, like currencies in a multi currency system. It works quite well for Products in an ecommerce website, where the product catalog can publish product updates, the Order service or Tax service might cache the Id, Name, Tax Code, and Price for example. It can be more of challenge for very large datasets, especially when they change frequently but are looked up infrequently. It that case you’ll need to make a trade-off decision between effort to maintain a cache and temporal coupling with the system of record for it.
Local Microservices
So, using Event Driven principles with message-oriented middleware, its possible that we can create microservices and deploy them in our remote locations.
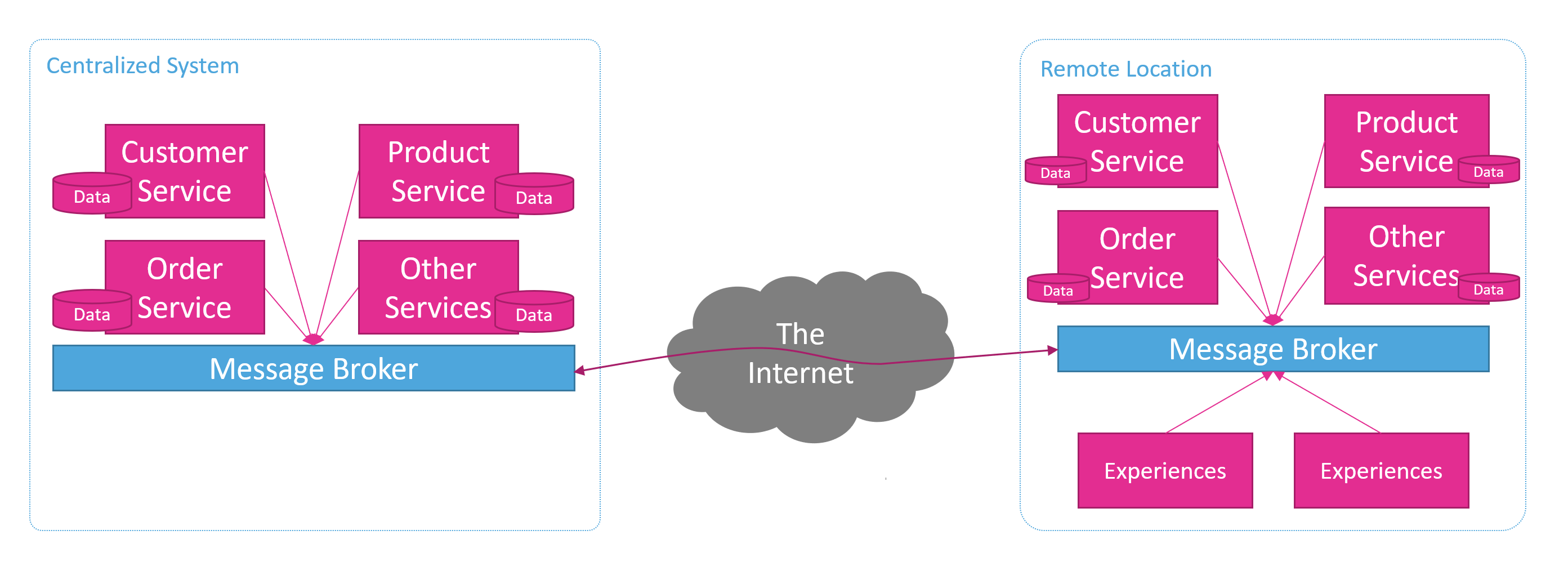
Experiences deployed in the remote locations will always use their local services through synchronous APIs or messaging on their local message broker. This simplifies their development as they can now assume that they are always online due to a reliable local area network.
The local services will synchronize the data and transactions with the centralized cloud version of the services. They will do this through the publication of events which can flow up to the central services across the connected message broker platform. The central services can receive and process these events and keep the central databases up to date.
Likewise, remote services will be able to receive updates from central systems, new records, changes to records, etc. This gives us the ability to do 2-way data synchronization, with auto stop/restart capability with minimal duplication, in close to real time. The bonus good news here is that all the complexity of managing that can be outsourced to a Message Broker vendor.
Independent Deployments
One of the other principles of microservices is ‘Independence’. Microservices should be able to be deployed and scaled independently from each other. This is facilitated by having clear boundaries and interfaces between the services to reduce coupling. When we build our Event Driven services in Business Oriented groups, we can get this independence by treating out Events as our contracts. Our Message Broker becomes our service discovery platform, removing the temporal coupling of synchronous calls and the configuration coupling of having to know the address of other services.
With that lower coupling we should be able to deploy services independently, allowing our product teams to work at their own pace and delivery functionality as soon as it’s ready.
This will provide a big benefit for our distributed deployments. We will be able to deploy smaller components, which means the bit transfer over the network will be shorter, the install should be faster, and we should be able to do this with little to no downtime.
Containers and Orchestration
Getting our small components copied to each of our remote locations, installed, and up and running is a challenge on its own. Luckily, it’s similar to the challenge we have getting our code from developer machines up to the cloud and running. It’s increasingly common to solve this deployment problem with Containers and Container Orchestration.
Running a Container Orchestrator in our remote locations can give us many benefits. If our development teams can publish their microservices as images to a registry, we can get our orchestrator to:
- Automatically download new copies of images
- Start our new images
- Health check our new images
- Turn off the old images
- Keep a minimum number of instances running across our remote machines
- Report the health status of our remote clusters to our central locations
All those tasks would be quite a bit of work for us to implement manually. We should be able to run all our remote infrastructure in containers too, from our databases to our message brokers.
Monitoring and Observability
Keeping very distributed systems like this running reliably and knowing when they are not is a challenge too. How do I track the uptime of my services, the completeness of my data synchronization? There are lots of options for monitoring, tools which can watch machine stats, check for running processes etc. If you use Containers and Orchestrators, they will do a lot of that monitoring for you too, reporting health of the clusters back for you.
However, I think it’s important to also aim for Observability in our system. To make it so it’s easy to see from the outside what’s happening in the inside. Our eventing idea can be used for this also. We can monitor our subscription’s queue length to see if things are being picked up, but we can also publish event’s specifically detailing health. We can publish performance counters, database call lengths, anything we think will be helpful in predicting, discovering, or diagnosing a problem.
Centralized systems in the cloud have many tools for managing this already, they have Azure App Insights for example, a service that you can publish all this data too. There are also tools like ELK stack and Prometheus that help to bring log files back to a central location and process them for metrics.
These are valuable tools and will help you, but these remote systems won’t always have access to them. If the internet is down, reporting to Azure App Insights is going to hard.
Our eventing system won’t achieve the impossible here, but it will piggyback on our existing solution of the message broker storing our messages reliably until we can confirm their transmission.
We could then record them anyway we like once they reach our cloud environment, even in App Insights at that point.
Summary
Occasionally Connected Servers isn’t a completely new problem, or a completely new solution. It is a growing trend of having geographically distributed services wanted to provide functionality close to the user but needing as good data as we can possibly get.
Event Driven Microservices running in Container clusters at the edge isn’t wholly unique either. Its a combination of technical approaches for solving this specific problem.
These won’t be the ideal solve for every problem in world, and there will continue to be advances on the tools and platforms that are available to support his. I am very exited about this growing trend as both a technologist, and as a user who wants good experiences wherever I go.
Comments